Feature flag management: Best practices
Feature flag management: Best practices
You’ve probably heard someone say, “A feature flag is just an if statement.” And in simple cases, that’s true. But when your organization has thousands of developers managing hundreds of feature flags—with complex targeting rules, audit trails, and dozens of microservices—those if statements get complicated fast. Especially if you don’t set things up properly from the start.
This guide shares what we’ve learned from helping teams run some of the largest feature flag deployments in the world, both through Unleash Open-Source and Unleash Enterprise.
The principles here don’t only apply to Unleash—they’re relevant for any large-scale feature flag system, whether you’re building your own or using a commercial solution. If you’re just getting started, check out our best practices for building and scaling feature flags.
In this guide, we’ll cover tips and best practices in five key focus areas to help you scale a feature flag system:
- Organize your feature flag code effectively
- Stay on top of technical debt
- Use feature flag lifecycle to optimize your development workflow
- Avoid common pitfalls when implementing feature flags
- Enable secure collaboration with flexible permissions
Organize your feature flag code effectively
Feature flags live in your codebase—and how you implement them matters. The choices you make when organizing flags can impact performance, testability, and long-term maintainability. Here are a few best practices we’ve learned from working with large-scale systems.
Define flags at the highest level of abstraction
Place feature flag evaluations as high in the stack as possible. For example, when testing a dark mode toggle or a new signup flow, evaluate the flag near the UI layer rather than scattering it across multiple components. This helps you:
- Simplify your code: Control feature behavior from a single point so that the rest of your system does not need to be aware of the flag.
- Test more easily: Isolate the feature for unit and integration testing.
- Clean up faster: Flags defined in one place are easier to find, maintain, and clean up when no longer needed.
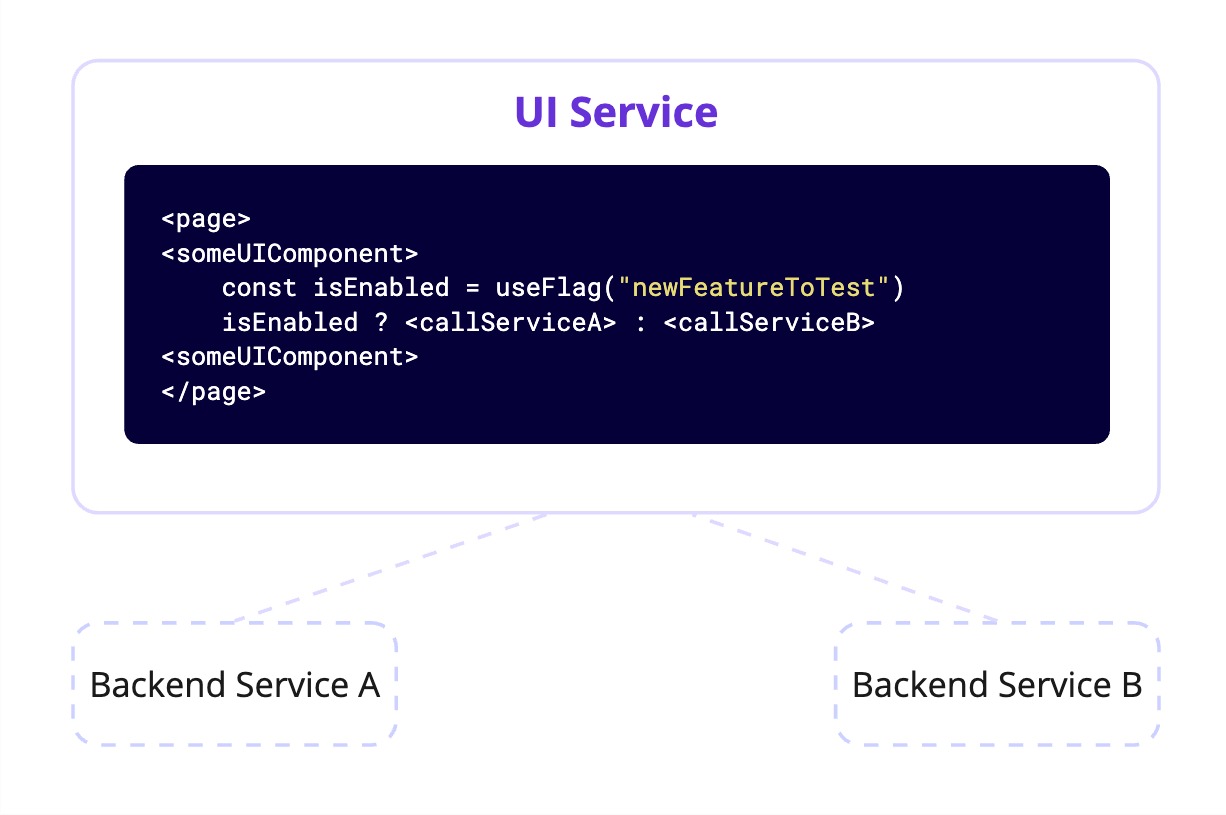
For backend logic—such as introducing a new database schema or optimizing a query—evaluate the flag close to the affected module. Make sure your code is easily testable. Evaluate the flag externally and inject the result, or provide two separate implementations. This makes it easier to write unit tests for both versions of the logic.
This enables:
- Focused testing: Evaluating the flag’s impact within the specified module simplifies testing and debugging. You only need to consider the immediate code’s behavior, making troubleshooting more efficient.
- Isolation: Evaluating close to the module helps isolate the impact of the feature flag, reducing the risk of unintended consequences in other parts of the codebase.
Whenever possible, evaluate your flag in a single place. Centralizing the evaluation simplifies your code and reduces the chances of inconsistent behavior.
Evaluate feature flags once per user request
When rolling out complex features, changes often span multiple parts of a system—whether that’s modules within a single application or services in a distributed architecture. It might seem convenient to use the same feature flag across all components and evaluate it locally in each one, but this can lead to problems.
As a user request moves through the system, it hits different parts at different times. Even with synchronized flag states, there’s a risk that the flag’s value changes between evaluations, resulting in inconsistent behavior for the user. Particularly in distributed systems, we cannot assume all parts of the system are perfectly synchronized, as networks are unreliable and can experience errors at any time. Most feature flag systems prioritize availability over consistency. By only evaluating a feature flag once, we guarantee a consistent experience for our users.
Using the same flag in multiple places fragments the control logic and breaks the single responsibility principle, making code harder to understand and maintain.
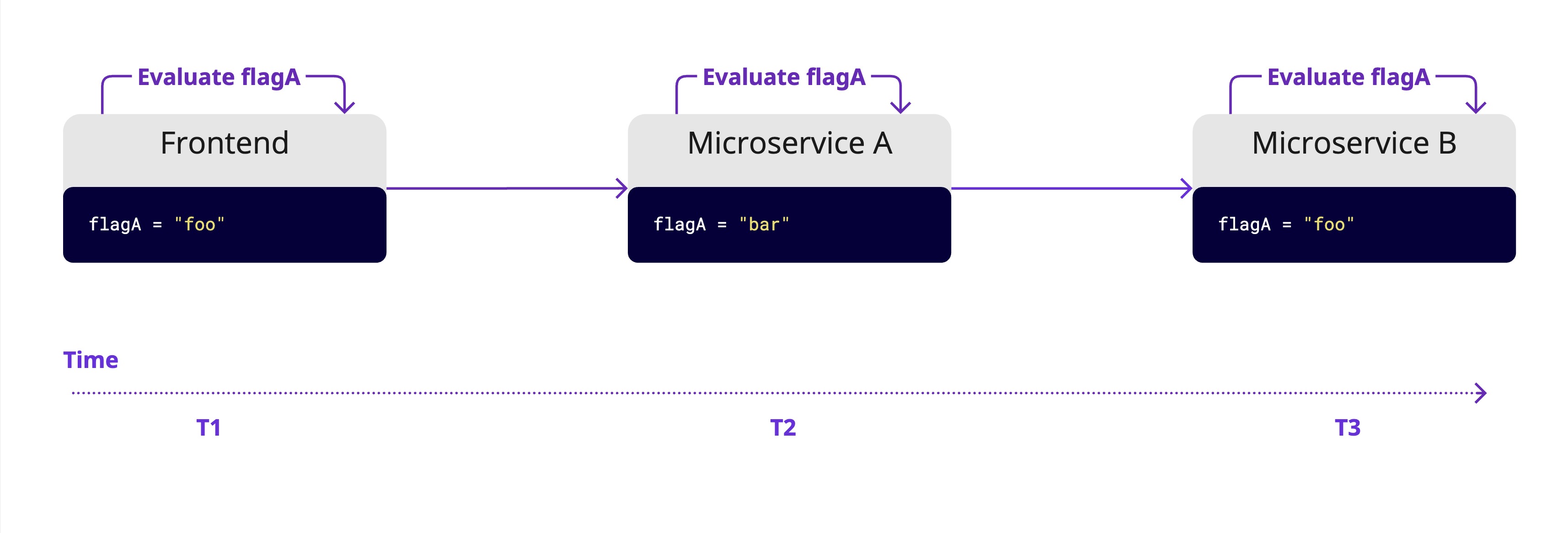
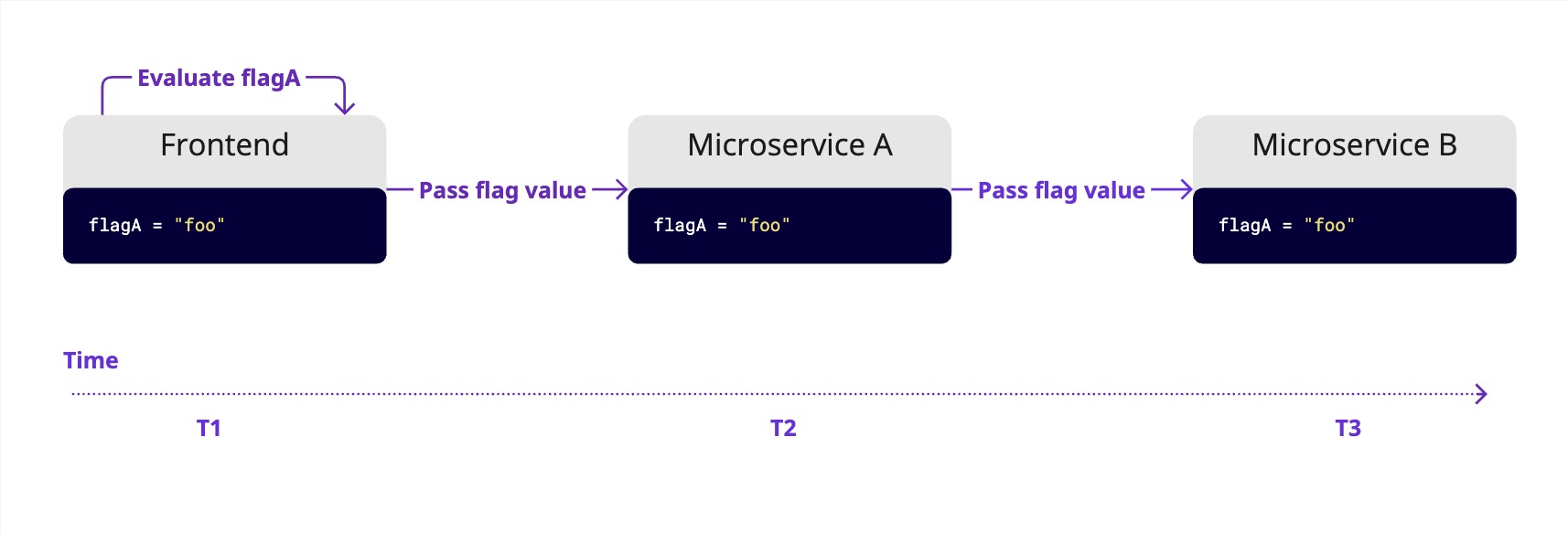
If a feature spans multiple parts of your system, evaluate the flag once, typically at the start of a user request, and pass the result rather than evaluating it separately in each place. This keeps behavior predictable and makes the codebase cleaner and easier to manage over time.
If you find yourself frequently passing flag results between services, consider whether those services are too tightly coupled. Passing flag values across service boundaries should be the exception, not the norm.
Stay on top of technical debt
Feature flags are powerful—they increase developer productivity, reduce risk, and support data-driven product decisions. But they also come with a catch: they’re a form of technical debt.
Technical debt builds up when flags stick around long after they’ve served their purpose. Over time, outdated or unused flags clutter your codebase, making it harder to read, test, and maintain. This slows down development and can even lead to bugs, security risks, or unexpected behavior—especially if old flags conflict with one another or expose sensitive features.
The simplest way to pay down flag debt? Track your flags and remove them when they’re no longer needed. Understanding the full lifecycle of a flag is key to keeping your codebase clean and your team moving fast.
Use feature flag lifecycle to optimize your development workflow
Every feature flag follows a lifecycle—even if your tooling doesn’t make it explicit. Understanding and tracking this lifecycle helps teams reduce technical debt and identify bottlenecks in the development workflow.
Here are the typical stages:
- Define: The flag is created, but no code has been written yet.
- Develop: Code is in progress. The feature isn’t live, but it’s being tested internally.
- Production: The feature is deployed to production and gradually rolled out to users.
- Cleanup: The team has decided to keep or discard the feature. The flag is still active, but it’s time to clean up the code.
- Archived: The flag is no longer needed. It’s been disabled and the associated code removed.
Tracking flags through these stages helps teams work smarter. Here’s how:
Spot bottlenecks
- Stuck in Define? Maybe requirements aren’t clear. Perhaps there are integration difficulties.
- Stuck in Develop? Could point to testing delays or bugs.
- Stuck in Production? Might be missing success criteria or user feedback.
- Stuck in Cleanup? Check for accumulating technical debt.
Clean up stale flags
Flags that outlive their purpose clutter the codebase and can lead to bugs or security risks. Regularly reviewing the lifecycle data helps you keep your code clean and secure.
Get actionable insights
Track metrics like time-to-production, rollback rates, or cleanup delays across teams. Over time, these insights can highlight efficiency gains—or uncover hidden slowdowns you might otherwise miss.
Avoid common pitfalls when implementing feature flags
When you work with feature flags at scale, some decisions seem smart in the moment—but can cause big headaches down the line. Here are five of the most common pitfalls we’ve seen:
Parent-child dependencies with complex targeting rules
At scale, it’s tempting to group related feature flags under a single parent flag to coordinate complex releases. The idea is simple: toggle one parent flag to enable or disable multiple child flags together. The parent can also serve as a global kill switch.
While this might work in theory, in practice it adds significant complexity. Now, enabling or disabling a feature isn’t just about a single flag—you have to account for both the parent and the child. It becomes easy to misconfigure rollouts or cause unintended behavior in production.
Things get even trickier when both parent and child flags have their own targeting rules. For example, if both are set to a 50% rollout, are you exposing the feature to 50% or 25% of users? The answer depends on how rollouts are calculated—which can be confusing and inconsistent.
Our advice: Keep it simple. If you use parent-child structures, avoid overlapping rollout rules, and document the hierarchy clearly. Better yet, try to design flags so that they can be managed independently.
Using feature flags to manage configuration
Both feature flags and configuration settings control an application’s behavior. However, it’s crucial to distinguish between feature flagging systems and configuration management systems and use each for its intended purpose.
Feature flags are temporary and dynamic. They give you runtime control to enable or disable functionality in a live environment—perfect for things like short-lived experiments, such as A/B testing or gradual rollouts.
Configurations, on the other hand, are usually static and long-lived. They often contain sensitive data like API keys or access credentials, which need to be encrypted and carefully managed. Using feature flags for configuration can create security vulnerabilities and operational issues. Most flag systems don’t encrypt values the way configuration management tools do.
A good rule of thumb is that if the data is static (you don’t expect it to change without application restart), needs encryption, or contains PII (personally identifiable information), manage it through a proper configuration system—not a feature flag.
Reusing feature flag names
Feature flag names need to be globally unique. In an ideal world, all flag references would be removed from the codebase as soon as a flag is archived—but in reality, that rarely happens. Using unique names helps protect new features from accidentally linking to old, unused flags that could unintentionally re-enable outdated behavior.
To avoid this risk, enforce a naming pattern at flag creation.
Using large targeting lists
When implementing feature flags, it’s crucial to aim for the quickest evaluation times possible. To achieve this, avoid relying on large inclusion lists—like thousands of specific user IDs—which can slow things down and become difficult to maintain.
Instead, focus on the underlying traits that qualify users for a feature. For example, rather than building a large list of beta testers, use a user attribute that can be managed in an external system. You can then configure your feature flag system to recognize the attributes that indicate that the user is part of the beta testing group.
This approach helps with:
- Maintainability: Adding a new user to the beta group is as simple as updating their group membership, without needing to edit the flag configuration.
- Memory usage: Storing a simple attribute is much more efficient than holding a list of thousands of user IDs in memory.
- Compliance: Restricting personal data to only the systems that need it makes it easier to stay compliant.
Defining core business logic in feature flags
Feature flags reduce the friction of releasing software, so it’s no surprise that teams who adopt them often expand their usage. This is generally a good thing—as long as archived flags are removed from the code base keeping tech debt down.
However, one common pitfall is using feature flags to control core business logic. Just like you shouldn’t use feature flags to manage application configuration, you should avoid embedding fundamental business rules in flags.
We recommend using feature flags to experiment with business logic, not to define it long-term. For example, let’s say you want to test whether premium users will adopt a new feature. Wrapping it in a flag lets you test and measure safely. But once you’ve decided that all premium users should have access, remove the flag and move the logic into your entitlement service or backend code.
So, if feature flags are so useful, why not use them for business logic? Here’s why:
Dependency on external services
We don’t recommend making core business logic dependent on any feature flag service. Even though Unleash is built with high resilience in mind—and designed to help your application keep running smoothly, even if you temporarily lose access to it—critical business functionality should never rely solely on the availability of an external service. This principle applies whether you’re using Unleash, another third-party provider, or a homegrown solution.
Complexity and maintainability
Embedding business logic within feature flags can make the codebase unnecessarily complex. Business rules can become scattered and entangled with feature flagging logic, making the code harder to read, understand, and maintain. When changes are needed, developers might have to navigate through many feature flags to find and update the relevant logic, increasing the risk of introducing bugs.
Performance implications
Feature flags are typically designed to be checked frequently and quickly, with minimal performance overhead. However, when feature flags are used to control business logic, they may involve more complex evaluations and data fetching, which can degrade application performance. This is particularly problematic for high-traffic applications where performance is critical.
Security risks
Business logic often involves access controls and entitlements. Using feature flags to manage these aspects can expose security vulnerabilities if not handled correctly. Feature flags might be toggled accidentally or maliciously, leading to unauthorized access or exposure of sensitive data.
Enable secure collaboration with flexible permissions
Before you add your first feature flag, you need to think about how organizational structure and processes that live outside of code affect your feature flag deployments. Also consider what legal and regulatory requirements you have—and how access, ownership, and collaboration is expected to change as your teams grow and your features evolve.
Align feature flags with your organizational and application structure
Any organization that designs a system will produce a design whose structure is a copy of the organization’s communication structure.
– Melvin Conway
Conway’s Law tells us that the systems we build naturally reflect the way our teams are structured—and that includes how we organize feature flags. Instead of working against this, it’s best to acknowledge it and design your feature flag system in a way that mirrors your organization’s structure.
For example, a large enterprise with thousands of developers might be structured around business units or product lines, not individual applications. If your flags are organized only by application, that mismatch can lead to confusion and make permission management harder than it needs to be.
Instead, organize flags in a way that matches how your teams actually work. People should be able to see the flags relevant to their work—whether that’s by team, product, project, or application. They should also be able to inspect a flag’s configuration and stay up to date on any changes.
Choose the right level of abstraction for grouping your flags:
- If your teams own features end-to-end, group flags by team.
- If you form cross-functional project teams, group flags by project.
Avoid putting all flags into one large group. While it might seem simpler, it quickly becomes difficult to manage. Permissions become complex and users are overwhelmed with irrelevant updates, making it harder to focus on what matters. Only include people in a flag group if they actually need to work with or track that flag.
Make flags searchable globally
Modern applications are composed of multiple services with many complex dependencies. While organizing flags by applications, teams, or business units is a good starting point, real-world services often exist across these organizational boundaries.
Just because a user doesn’t normally work with a flag doesn’t mean they won’t need to find it. However, you don’t need to show every flag by default—especially those outside a user’s main scope. What matters is that all flags are searchable. When someone searches for a flag, they should be able to view its configuration and ownership, so they can request access or submit a change request if needed.
This is why feature flag systems should be open by default.
There are also valid use cases for excluding flags from global search. For example, during sensitive projects, it may be necessary to hide flags that could expose confidential changes. Your system should support private flags in special cases—but those should remain the exception, not the norm.
Design for flag permissions to change over time
The owner or maintainer of a flag may change over time as the feature it controls evolves across its lifecycle.
For instance, a developer might initially create a flag to hide incomplete code while working in trunk-based development model. At this stage, the flag exists to hide unfinished code and is owned and managed by the developer.
Later, when the feature is ready to roll out, the purpose of the flag shifts—from hiding unfinished work to managing exposure to users. With this shift, ownership often becomes shared:
- For simple rollouts, the developer might remain the main owner, gradually enabling the feature while monitoring for issues.
- For more complex rollouts, especially when business context matters, the developer may still manage the flag, but a product owner or Customer Success Manager might control targeting rules or decide which users see the feature first.
In B2B environments, for instance, it’s common for customer-facing teams to guide rollouts based on account needs. These teams need the appropriate access and ownership—while still keeping developers in the loop for technical oversight.
Feature flag permissions should be dynamic and reflect real-world collaboration. You should also design your permission system to easily adapt to common scenarios like:
- Access is misconfigured—someone needs access or has access they shouldn’t.
- Project requirements shift midway through development.
- Project ownership changes due to role or team changes.
- Organizational structure evolves and teams are reorganized.
Get flag permissions right—and audit everything
As features move through their lifecycle, different teams will need access to the same flags—but not everyone should have the same level of control.
Here’s a sample list of actions users may need to perform on a feature flag, each requiring its own permission setting:
- Create
- Delete
- Turn on / off
- Configure targeting
- Change rollout
- Read configuration
- Update configuration
Let’s walk through a simple example: a product manager is collaborating with a developer to test a beta feature.
The developer should likely have full control—turning the flag on or off as needed. But what about the product manager? That depends on how your organization handles ownership and responsibilities. Your feature flag system should support fine-grained permissions to reflect those organizational needs.
Take targeting and rollout strategies, for instance:
- You might allow the product manager to update targeting rules but not control rollout percentages.
- Or, they may have full access to both, but changes must go through an approval workflow before being applied.
These choices often reflect broader compliance or security policies. The key is flexibility: your flag system should let you tailor permissions based on roles, use cases, and risk levels.
Just as important as getting permissions right is tracking what happens to your flags. A robust audit log is critical. It helps answer questions like:
- Who changed a targeting rule—and when?
- What configuration was live during an incident?
- Are approval workflows being followed?
- Do we need tighter controls or better communication?
And in the rare case of malicious behavior, an audit trail can help you pinpoint the issue and respond quickly.
Align flag permissions with your global access controls
Your organization likely already defines user groups, for example by role (such as developers, operations, marketing) or by business unit. Use those existing structures to manage feature flag permissions. This makes it easier to assign the right access levels and keeps your permission model consistent across systems.
Your flag system should integrate with your single sign-on (SSO) provider. That way, when a user is added to or removed from a group in your central directory, their access to the flag system updates automatically.
Managing access is complex—so don’t manage it in multiple places. Let your global permissions drive flag access and keep everything in sync.
Implement flag approval workflows early
Depending on the industry and legal framework you’re operating in, you’ll need varying levels of approval for a feature flag change to go into production. Whether your process is lightweight or highly controlled, your feature flag system should support it.
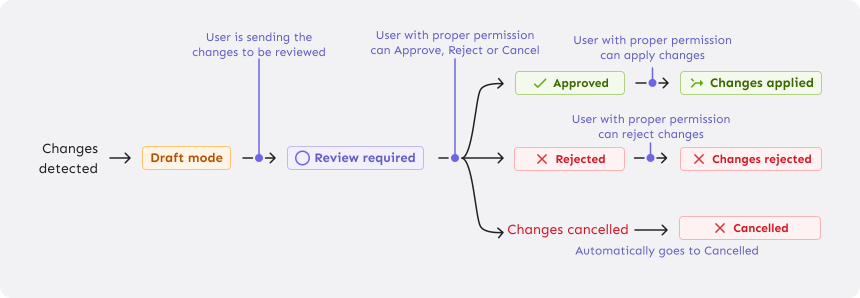
In regulated industries, peer review is often required before changes reach production—commonly known as the four-eyes principle. Think of it like a pull request: users should be able to bundle related changes across multiple flags into a single request, preview the impact, and submit it for review. Reviewers should have clear visibility into what’s changing and what the new configuration will look like.
Even if your organization doesn’t require approvals, having an optional review step is still valuable, as it allows you to:
- Coordinate multiple changes: Grouping related flag updates ensures they go live together, preventing inconsistent or incomplete rollouts.
- Prevent accidental changes: A quick review adds a layer of safety, so unfinished code won’t accidentally be exposed.
- Double-check outcomes: Reviewing changes in context helps you confirm that you’re delivering what you intended.
Staying in control with feature flags at scale
These best practices are based on insights from working with some of the world’s largest organizations. What we’ve learned is that careful planning, discipline, and the right systems in place help you stay in control, no matter the size of your organization.
By aligning feature flags with your organizational structure, and keeping them globally searchable, you lay the foundation for a system that’s easy to maintain and scale. Instrumenting your code properly, addressing technical debt regularly, and maintaining a flexible permission system ensures strong performance and security over time. And by avoiding common pitfalls—like embedding business logic or managing config through flags—you keep your system clean and manageable.
Feature flags are a powerful tool for delivering software efficiently while maintaining security and compliance. For developers working in large organizations, that is the best of both worlds. Following the practices in this guide will help you get the most value from feature flags without getting lost in complexity.
The key to success at scale? Clear processes, regular maintenance, and a commitment to best practices. With these in place, you can rely on feature flags to drive innovation and improve your software development lifecycle.
This guide focused on using feature flags at scale. For advice on building and scaling the flag system itself, check out our feature flag best practices guide.