Managing feature flags in your codebase
How you manage feature flags in code directly impacts the performance, testability, and long-term maintainability of your applications. Without the right processes and structure, flags quickly become tech debt, making your code harder to understand and risky to change.
In this guide, we explore hands-on strategies for managing feature flags in your code effectively. We’ll give you practical recommendations and code examples to help you build a system that’s reliable, scalable, and easy to maintain.
We’ll cover how to:
- Define and store flag names in code.
- Architect flag evaluations with an abstraction layer to keep your code clean.
- Structure conditional logic to simplify flag cleanup.
- Manage flags in microservices.
- Minimize tech debt and manage the flag lifecycle to prevent technical debt.
Building on a foundation of clean code
Before we dive into specifics, remember that good software design practices make everything easier. Principles like modularity and a clear separation of concerns are your best friends when integrating feature flags.
Here are the goals we’re aiming for:
- Clarity: Your feature flag logic should be easy to find and understand. Any developer on your team should be able to quickly grasp what a flag does and how it affects the system.
- Maintainability: Adding, changing, and removing flags should be a simple and low-risk process.
- Testability: Your code under a flag should be easily and reliably testable.
- Scalability: Your approach needs to handle a growing number of flags and developers without increasing code complexity.
Defining and storing flag names
Your first step is deciding how to represent and store flag names in code. These identifiers are the critical link between your application and your feature flag configurations in the Unleash Admin UI. A disorganized approach here can quickly lead to typos, inconsistencies, and difficulty in tracking down where a flag is used.
We recommend centralizing your flag name definitions using constants or enums. This approach establishes a single source of truth for all flag names in your application.
Why centralize definitions?
- Avoids inconsistencies or errors: Using constants or enums prevents typos and inconsistencies that arise from scattering string literals (
"my-new-feature") throughout the application. Your compiler or linter can catch errors for you. - Improves discoverability: A central file acts as a manifest of all flags used in the application, making it easy for developers to see what’s available and how flags are named.
- Simplifies refactoring and cleanup: If you need to change a flag’s name in your code (for example, to fix a typo), you only need to update it in one place.
Here is a simple and highly effective pattern using TypeScript’s as const feature. It’s robust, type-safe, and easy to understand.
For applications that need even stricter type safety or rely heavily on flag variants, you can use a more advanced pattern. This approach, used within the Unleash codebase itself, combines union and mapped types for maximum compile-time checking.
Finally, no matter which pattern you choose, you should avoid dynamic flag names. Constructing flag names at runtime (such as, {domain} + "_feature") prevents static analysis, making it nearly impossible to find all references to a flag automatically. It makes clean-up with automated tools more difficult.
Architecting flag evaluation
How and where you check a flag’s state is one of the most important architectural decisions you’ll make. A well-designed evaluation strategy keeps your code clean and your system’s behavior predictable.
Use an abstraction layer
Directly calling the Unleash SDK’s unleash.isEnabled() throughout your codebase tightly couples your application to the specific SDK implementation.
Instead, we recommend implementing an abstraction layer, often called a “wrapper”, to encapsulate all interactions with the Unleash SDK. This service becomes the single entry point for all feature flag checks in your application.
Why build an abstraction layer?
- Vendor abstraction: If you ever switch feature flagging providers, you only need to update your wrapper instead of hunting for SDK calls across the entire codebase.
- Centralized control: It gives you a single place to manage logging, performance monitoring, and robust error handling for all flag checks.
- Improved readability: Methods with business-friendly names (
canUserSeeNewProfilePage()) make the code’s intent clearer than a genericisEnabled("newUserProfilePage").
Handling variant payloads inside your wrapper
This wrapper is also a good place to validate any feature flag payload you receive from Unleash.
While using variant payloads for dynamic configuration enables flexibility and rapid iteration, it also introduces risk. Since the variant payload is managed in a UI, a change can have unintended consequences on the application’s behavior or appearance, even if the JSON itself is syntactically valid.
If you decide to use variant payloads, we recommend enforcing a four-eyes approval process, so any change must be reviewed and approved by a second team member before it can be saved. In addition, you should test payloads with internal users first before exposing them to real users.
Then, implement additional guardrails in your wrapper to validate the payload structure and return a safe default value if the data is invalid.
Evaluate flags at the right level and time
For a given user request, evaluate a feature flag once at the highest practical level of your application stack. If multiple components need to act on the same flag, propagate the result of that evaluation (the true/false value or the feature flag variant) downstream rather than re-evaluating the flag in each place.
This prevents “flag-aware” logic from spreading deep into your application’s components, making them simpler and easier to test.
In a backend application, the highest level is often the controller or the entry point of a service request. The controller evaluates the flag and then directs the application to use either the new or old logic path.
In a frontend framework like React, evaluate the flag in a top-level container component. This component then renders different child components based on the flag’s state, passing down data as props. The child components themselves remain unaware of the feature flag.
Backend
Frontend
Why evaluate once?
- Consistency: It ensures a user sees the same feature state throughout their interaction. Evaluating the same flag multiple times during a single request could yield different results if the flag’s configuration is changed mid-request, leading to a broken or confusing user experience.
- Simplicity: It prevents “flag-aware” logic from spreading deep into your application’s components, making them simpler and easier to test.
Structuring conditional logic
The way you structure your conditional logic for your flags has a major impact on readability and, most importantly, on how easy it is to clean up later.
For the vast majority of cases, a simple if/else statement is the best approach. It’s direct, easy to understand, and straightforward to remove.
The primary goal is to keep the conditional logic localized and simple. When it’s time for cleanup, the task is trivial: delete the if and the else block, and the new code path remains.
Using design patterns
Design patterns like the Strategy pattern or the Factory pattern are sometimes used in place of direct conditional logic. For example, the strategy pattern uses a flag to select a concrete implementation of a shared interface at runtime, encapsulating different behaviors into distinct classes.
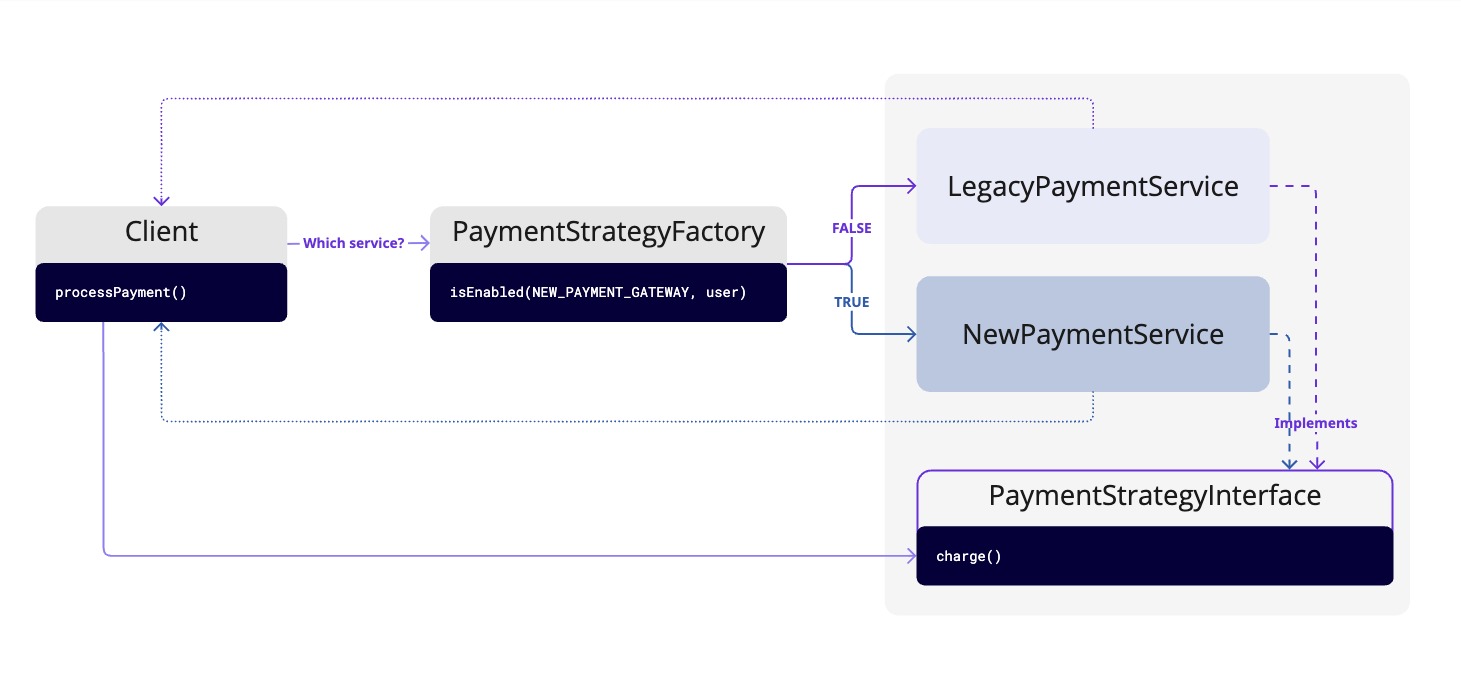
The strategy pattern is well-suited for certain Permission flags that grant premium users access to an advanced feature, or for long-term Kill switches that toggle a core system component. For these complex, multi-faceted features with distinct and interchangeable behaviors, the pattern can be a powerful tool for maintaining a clean, scalable, and testable codebase.
TypeScript
Java
However, the majority of feature flags control small, temporary changes. For most Release, Experiment, and Operational flags, the strategy pattern introduces unnecessary overhead. It makes the eventual cleanup process far more complex than removing a simple if/else block. Furthermore, because the pattern scales poorly when multiple flags interact, a direct conditional statement is almost always the cleaner and more maintainable choice for these temporary flags.
Managing flags in microservices
Managing feature flags in a microservices architecture requires guaranteeing consistency. When a single user request triggers a chain of calls across multiple services, each service needs to operate on the same feature state.
You might assume that if each service evaluates a flag with the same user context, the result will be consistent. In a perfectly static system, this is true. However, in a live production environment, flag configurations can change. This introduces a critical race condition: a flag can be toggled mid-request, causing different services in the same call chain to get different results.
Imagine a NEW_PRICING_MODEL flag is active:
- The
gateway-servicereceives the request, sees the flag is on, and calls theproduct-service. - The
product-servicealso sees the flag is on and prepares to show a promotional banner. It calls thepricing-service. - In the milliseconds between these calls, an engineer turns off the flag in the Unleash UI due to an issue.
- The
pricing-servicenow evaluates the flag, sees it as off, and returns the standard price.
The result? A confused user who sees a promotional banner but gets charged the old price.
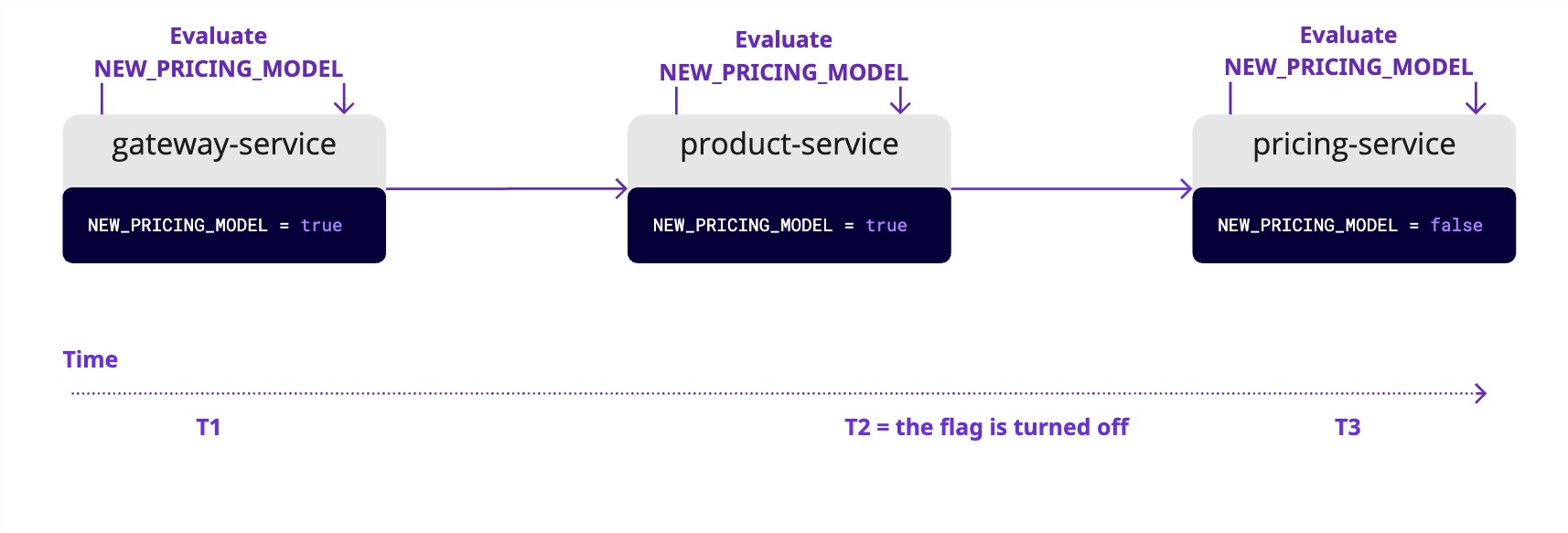
The solution is to evaluate a feature flag’s state exactly one time at the “edge” of your system—typically in an API Gateway or the first service that receives the external request. Then, you must propagate the result of that evaluation—the true/false or a specific variant—downstream to all other services.
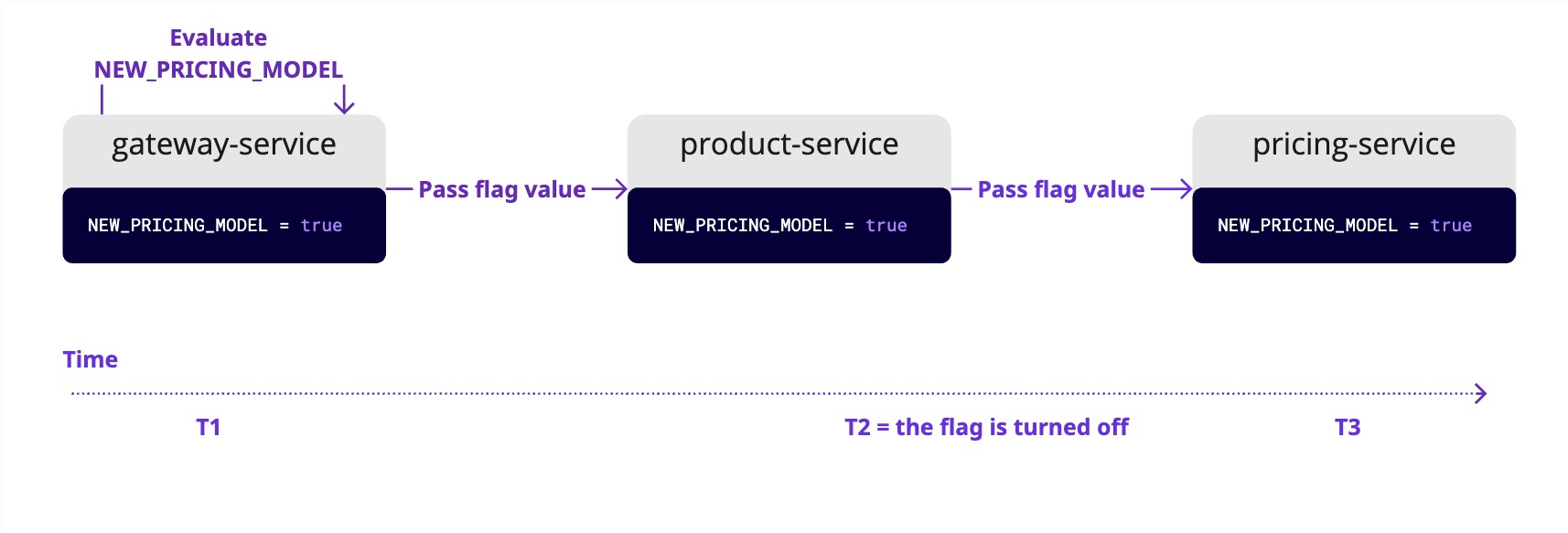
To make this work, downstream services need the initial flag evaluation result and the user context (ID, location, etc.) used to make them. The standard, most robust way to achieve this is with OpenTelemetry Baggage.
While OpenTelemetry is known for distributed tracing, its Baggage specification is purpose-built to carry application-defined key-value pairs across process boundaries. It’s the ideal mechanism for this use case.
Here’s how it works:
- The
gateway-servicereceives a request, authenticates the user, and evaluates all necessary flags. - It uses the OpenTelemetry SDK to add the user context and the flag evaluation result to the current baggage.
- When the
gateway-servicemakes an HTTP call to a downstream service, the OpenTelemetry instrumentation automatically serializes the baggage into thebaggageHTTP header and sends it. - The downstream service’s instrumentation automatically receives this header, deserializes it, and makes the baggage available to your application code.
Java
Python
Minimizing tech debt and managing the flag lifecycle
Let’s face it: stale flags are tech debt. Without a plan, your codebase will fill up with forgotten and risky flags. The only way to win is with a clear process for managing their entire lifecycle.
Naming conventions and flag metadata
The first line of defense against flag debt is clarity. A flag named temp_fix_v2 is a mystery waiting to happen. A good name provides immediate context about the flag’s purpose and owner, both in the Unleash UI and in your code.
A highly effective pattern is: [team]_[feature-name]. For example: checkout_multistep-payment-flow.
The [team] prefix is invaluable when multiple teams share a single Unleash project, as it clarifies ownership. However, if you organize your Unleash instance with per-team projects, this prefix may be unnecessary, though it can still be helpful for searching through code.
[feature-name] should be a short, descriptive slug for the feature.
While you can add more information directly to the name, such as an issue number or a full issue name, this is a trade-off. It can make the flag name long and complicated to work with in code.
A better practice is to keep the name clean and use Unleash’s built-in metadata features for richer context:
- Use external links: Instead of putting an issue number like JIRA-376 in the name, use the external links feature in Unleash to connect the flag directly to the corresponding Jira ticket, GitHub issue, or design document.
- Write a clear description: Use the description field to explain what the flag does, what the rollout plan is, and any additional context that may be relevant.
This approach keeps flag names readable in your code while ensuring all the necessary context for lifecycle management is available in the Unleash UI. Once you’ve identified a naming convention that works, you can enforce them at the project level.
Flag cleanup best practices
You can use a flag’s lifecycle data and automated reminders to ensure flags are removed from your code once they have served their purpose.
Here’s our recommended workflow for flag cleanup:
-
Update the flag’s lifecycle status: Once a feature is stable and fully rolled out, mark it as Completed in Unleash. If you forget, Unleash will prompt you to update the status for stale flags that are no longer sending metrics. This moves the flag to the Cleanup lifecycle stage, creating a clear backlog for removal.
-
Clean up the code: Remove the conditional logic, any old code paths, the flag’s definition from your central file, and any helper methods from your wrapper. This ensures you remove dead code and reduce complexity.
-
Test and deploy: Run your tests to ensure everything still works as expected, then deploy your changes.
-
Archive the flag in Unleash: Finally, archive the flag in the Unleash UI. Don’t delete it—archiving preserves its history for auditing and analysis.
Just hoping that people remember to clean up is not a sustainable strategy. You need to automate your governance process.
Here are some practical tips:
- Automated ticketing: Use webhooks or integrations to automatically create “Remove Flag” tickets.
- Scheduled reviews: Make flag reviews a part of your process, for example your planning. Teams should justify a flag’s existence or schedule them for removal.
- Update “Definition of Done”: A feature isn’t “done” until its associated feature flag has been removed from the code and archived in Unleash.
- Use AI to speed up the cleanup: Rely on AI coding assistants to automate and fix flag removal issues.
Testing with feature flags
There is no single “right” way to test with feature flags, as every organization has a different testing strategy. The key is to build confidence that your application remains stable regardless of which flags are active. An effective approach typically involves a combination of strategies across different levels of the testing pyramid.
A common fear is that flags will cause a “combinatorial explosion” of test cases. You don’t need to test every possible combination. Instead, focus on a few high-value scenarios.
Unit tests
At the unit level, the focus is narrow: does this specific piece of code work correctly when its controlling flag is on and when it’s off?
For any unit of code affected by a flag, you should have tests that cover both states:
- Flag on: Verifies the new code path works as expected.
- Flag off: Verifies the old code path still works and the new code is not executed.
Component and E2E tests
For broader tests that cover a single service, component, or the entire application, you need a strategy to handle the growing number of flags. Here are some common states to cover:
- Baseline state = all flags off: These tests run with all feature flags turned off, simulating your stable production environment. It verifies that adding new, dormant flag-protected code hasn’t caused regressions in existing functionality.
- New features state = all flags on: This suite runs with all (or most) feature flags enabled. Its purpose is to catch unexpected, negative interactions between multiple new features that might be developed in parallel. It helps ensure that the application is functioning as expected in its most feature-rich state.
- Common combinations: For mature applications, it may be useful to test the most common combination of flags that your users experience. This pragmatic approach focuses testing effort on the configurations that have the biggest real-world impact.
- SDK fallback state: What happens if Unleash is unavailable? Does your wrapper handle it gracefully and fall back to safe defaults?
Testing in production
The real superpower that flags give you is testing in production—safely.
This doesn’t mean showing bugs to your customers. It means using targeting rules to enable a feature only for your internal teams in the live production environment.
For example, you can set a flag to be “on” only for users with an @your-company.com email address.
This allows your team to interact with the new feature on real production infrastructure, with real data—a context that is impossible to perfectly replicate in a staging environment. If you find a bug, it has zero impact on real users. You can fix it and then release it with confidence.
Key takeaways
To wrap things up, managing feature flags effectively boils down to a few core, hands-on practices.
First, centralize flag definitions in a single file to prevent errors and make them easy to find and remove. Second, always build an abstraction layer or wrapper around the SDK; this gives you a single point for error handling and simplifies future migrations.
For structuring your conditional logic, a simple if/else is usually the best choice for temporary flags, as it’s the easiest to clean up.
Finally, evaluate flags once at the highest reasonable level in your application. In the cases where a feature spans multiple components, propagate the result downstream rather than re-evaluating—this is especially crucial in a microservices architecture where it ensures a consistent user experience.
Frequently asked questions (FAQs)
This FAQ section addresses common questions about using feature flags in code, focusing on flag evaluation in different architectures, conditional logic implementation, and testing.
Where should I define my feature flag names in the code? Centralize them in a dedicated file using constants or enums. This creates a single source of truth, prevents typos, and makes cleanup easier.
Should I call the Unleash SDK directly everywhere or build a helper service? Build a wrapper (an abstraction layer). It decouples your app from the SDK, gives you a central place for error handling and logging, and makes future migrations painless.
How do I handle code for complex features controlled by flags? Start with a simple if/else statement. This is the cleanest and easiest-to-maintain solution for most cases. The Strategy pattern should be reserved for complex, long-lived flags like kill switches or permissions, as it can introduce unnecessary complexity for short-lived release flags.
How do we avoid flag debt? Have a process! Use strict naming conventions, link flags to tickets in Unleash, make flag removal part of your “Definition of Done,” and automate cleanup reminders.
When and how should I remove a feature flag from the code? Once the flag is stable at 100% rollout (or permanently off). The process is: remove the conditional logic and old code, delete the flag definition, and then archive the flag in the Unleash UI.
Can you use feature flags in microservices? Absolutely! Evaluate the flag once in the first service that gets the request (for example, your API gateway). Then, propagate the result of the evaluation (the true/false result or assigned variant) to downstream services that need it using OpenTelemetry Baggage or custom HTTP headers. This guarantees consistency.
What’s the best way to evaluate a feature flag in code? Evaluate it once per request at the highest logical point in your application. If the flag affects multiple components, pass the boolean result down to those that need it rather than re-evaluating. This ensures a consistent user experience for that entire interaction.